
How would you design Memory Systems for production-ready AI Agent.
How to give AI agents the ability to remember things across sessions, across users, across time while also architecting the storage, retrieval, and lifecycle pipeline underneath it.

Hello “👋”
Welcome to another week, another opportunity to become a Great Backend Engineer.
Today's issue is brought to you by Masteringbackend → An all-in-one platform that helps backend engineers become highly-paid backend and AI engineers by leveraging a practical-based learning approach.
Here's another issue of Backend Weekly — your favorite newsletter on mastering AI backend engineering through real-world systems and interview design questions.
Before we dive in:
If you’ve asked your AI agents the same question twice, in two different sessions, and it doesn’t remember the first answer, or doesn’t remember that it already solved this exact problem for you yesterday.
That’s because LLMs are stateless. Every request starts from zero. It lacks Memory. The kind that persists across sessions, accumulates knowledge over time, and makes an agent feel like it knows you.
Memory is not built in. It’s built by backend engineers like yourself.
If you want to be the engineer who builds these systems, not just the one who uses them, join us on Monday's AMA session to learn more about the “Build 10 AI Products in 30 Days” Bootcamp.
This is the AI Backend Interview Series on Backend Weekly, which airs every Saturday now.
In this series, I will guide you through answering common AI backend engineering interview questions, covering topics such as AI backend system design, vector databases, memory systems, microservices, API design, and databases.
Let's get started with episode 4 (Episode 3 Here):
The Interview Scenario
You’re in an AI backend interview.
They ask:
“How would you design a memory system that allows AI agents to remember context across sessions — including user preferences, past interactions, and learned behaviors — at production scale?”
Here’s how to approach it:
When your AI Agent makes an LLM call, it can feel like a blank slate.
The model receives a prompt, generates a response, and immediately forgets everything. Sometimes, even in the next call, it still won’t have context or knowledge of the user or previous conversations.
This is fine for a playground demo. It is not fine for production AI agents, I mean real AI Agents that assist customers, manage workflows, or collaborate with engineering teams across days, weeks, and months.
Memory is what turns a stateless text generator into an agent that actually knows things.
And here’s the part that most people miss:
Memory is not an AI problem. It is a backend engineering problem.
To explain further. It’s storage. It’s retrieval. It’s lifecycle management. It’s scoping, access control, and consistency guarantees. That’s exactly what backend engineers have been doing.
Let’s start from the first principle.
Why LLMs Don’t Have Memory
Start here with your interviewer. LLMs process a context window, which is a fixed-size token buffer that contains everything the model can “see” during a single request. As of 2026, context windows range from 128K to 1M+ tokens.
A larger context window does not solve the memory problem. It just delays it. You know, like when you compare RAM and SSD (disk)
Why?
Let’s explore the reasons:
Context windows are ephemeral. The content disappears after the response is generated. The next API call starts empty with nothing persisted.
Token cost scales linearly. Stuffing an entire conversation history into every request is expensive. A full-context approach on a 200K-token window can cost 10–50× more than a memory-augmented approach that injects only the relevant facts.
Recall degrades with length. Research consistently shows that LLMs perform worse at retrieving specific facts from extremely long prompts. More context doesn’t mean better understanding. It often means more noise.
The solution is not a bigger context window. The solution is a system that selectively stores, consolidates, and retrieves the right information at the right time, and injects only what’s relevant into a manageable prompt.
That system is called memory.
Types of Memory
By the end of 2026, the AI engineering community will have converged on three memory types.
These mirror human cognitive architecture, and that’s not a coincidence. If you think about it for a second, they solve the same fundamental problem:
What to remember, at what granularity, and for how long.
Discuss each with your interviewer.
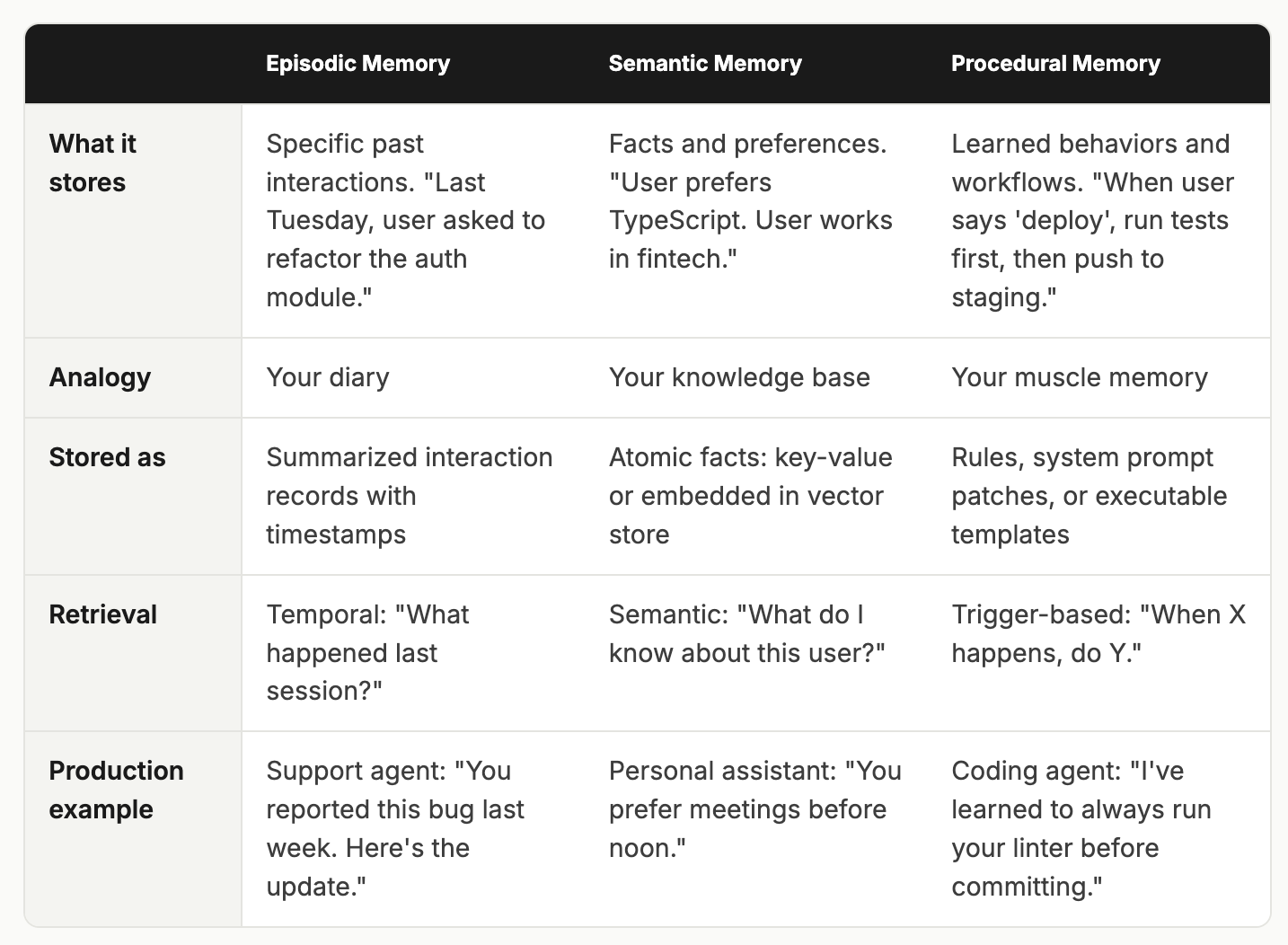
Most production systems implement semantic and episodic memory as a minimum.
In procedural memory, agents rewrite their own instructions based on experience. It is more advanced and is primarily seen in frameworks like Letta (formerly MemGPT) and LangMem.
Tell your interviewer this:
The three memory types are not an either/or choice. A production memory system uses all three, scored and blended at retrieval time.
The Memory Architecture
Every memory system, regardless of framework, should follow the same four-stage pipeline.
This is the architecture you’ll design as a backend engineer.

Let me break each stage down for you.
[Stage 1 — Extract]: Turning Conversations into Facts
Raw conversation messages are not in memory. They’re noise. The extraction stage uses an LLM call to distill a conversation into atomic, structured facts.
Here’s what extraction looks like in code:
import { Memory } from "mem0ai/oss";
const client = new Memory({ apiKey: process.env.MEM0_API_KEY });
// After a conversation, add the messages to memory
await client.add(
[
{ role: "user", content: "I work at Acme Corp in the billing team. We use Stripe." },
{ role: "assistant", content: "Got it! I'll keep that in mind for future billing discussions." },
{ role: "user", content: "Can you always use TypeScript for code examples?" },
{ role: "assistant", content: "Absolutely — TypeScript it is from now on." },
],
{
user_id: "user_abc123", // scoped to this user
agent_id: "coding-agent", // scoped to this agent
}
);Behind the scenes, the extraction pipeline converts those four messages into discrete facts:
// Extracted memories (stored as separate records):
// 1. "User works at Acme Corp in the billing team" - semantic
// 2. "User's company uses Stripe for payments" - semantic
// 3. "User prefers TypeScript for code examples" - proceduralEach fact is embedded as a vector, tagged with metadata (user ID, session ID, timestamp, memory type), and stored. The raw conversation is not stored, only the distilled facts.
[Stage 2 — Consolidate]: Deduplication and Conflict Resolution
This is where most memory systems fail. Without consolidation, memory accumulates contradictions and duplicates over time.
The user says “I work at Acme Corp” in session 1, then “I just joined Stripe” in session 30. Both facts exist in the vector store.
Which one is true?
Think about it.
The consolidation stage compares each extracted fact against existing memories and applies one of four operations:
ADD: If it’s a new fact, no similar existing memory. Insert it.
UPDATE: If similar memory exists, but the details have changed, then replace it. For example, “Works at Acme Corp” becomes “Works at Stripe.”
DELETE: New fact explicitly contradicts an old one. Remove the old one.
NOOP: If fact already exists in memory. Skip it.
This is implemented as a tool-calling pattern that the LLM examines the candidate’s fact alongside similar existing memories and decides which operation to apply.
[Stage 3 — Store]: The Dual-Store Architecture
Production memory systems use a dual-store architecture.
A vector store for semantic search and an entity index for structured relationships.
Let me explain it with an illustration:
// Vector store: fast semantic retrieval
// "Find memories similar to 'billing API architecture'"
// → Returns: "User works on billing team", "Uses Stripe", "Prefers microservices"
// Entity index: structured relationship traversal
// "What do I know about entity 'Acme Corp'?"
// → Returns: "User works there", "Uses Stripe", "Billing team", "500 employees"Why both?
This is important. Explain it in detail to your interviewer.
Vectors provide semantic flexibility because you can find related memories even when the wording is completely different. Additionally, Entity indexing provides relational integrity, meaning you can traverse relationships between entities without semantic drift.
For the vector store, you can discuss any technology you’re already comfortable with that works.
pgvector
Qdrant
Chroma
Pinecone
Redis
However, for the entity index, Mem0 now uses a built-in entity collection rather than requiring an external graph database. So that during extraction time, entities are identified and stored in a parallel collection, then matched at retrieval time.
[Stage 4 — Retrieve]: Multi-Signal Scoring
Retrieval is where memory becomes useful. When a new user message arrives, the system must decide:
Which memories are relevant to this specific request?
Modern retrieval runs three scoring passes in parallel:
async function retrieveMemories(query: string, userId: string) {
// 1. Semantic similarity — embed query, find nearest vectors
const semanticResults = await vectorStore.search({
embedding: await embed(query),
filter: { user_id: userId },
topK: 20,
});
// 2. Keyword matching — exact term overlap for precision
const keywordResults = await keywordIndex.search({
query,
filter: { user_id: userId },
topK: 20,
});
// 3. Entity matching — extract entities from query, match against entity index
const entities = extractEntities(query); // ["Stripe", "billing API"]
const entityResults = await entityIndex.search({
entities,
filter: { user_id: userId },
});
// 4. Fuse scores: relevance × recency × type_weight
const fused = fuseScores(semanticResults, keywordResults, entityResults, {
semanticWeight: 0.6,
keywordWeight: 0.25,
entityWeight: 0.15,
recencyDecay: 0.95, // older memories score slightly lower
});
// 5. Return top-5 under 200 token budget
return selectWithinTokenBudget(fused, { maxTokens: 200 });
}The fused results are injected into the LLM prompt as a system-level context block. The model sees them as pre-existing knowledge, not as search results. This is what makes the agent feel like it "remembers."
Next, let’s talk about “Who Remembers What”, so that you can discuss it with your interviewer.
Memory Scoping: Who Remembers What
In production, you don’t have one global memory. You have scoped memories that determine who can see what.
Discuss this with your interviewer because it’s the access control layer of your memory system.
User-scoped: Memories specific to one user. For example, “This user prefers dark mode.” Only retrieved when that user is active. This is the most common scope.
Session-scoped: Memories that expire with the session. Short-term working memory. For example, “In this session, we’re refactoring the auth module.” Cleared on session end.
Agent-scoped: Knowledge the agent has learned across all users. “This codebase uses Prisma ORM.” Retrieved regardless of which user is active.
Organization-scoped: Shared memories across a team. “Acme Corp’s coding standards require 80% test coverage.” Retrieved for any user in that org.
Each memory record is tagged with its scope IDs at write time, and filtered by those IDs at read time.
This is not conceptually different from row-level security in PostgreSQL or tenant isolation in a multi-tenant API. It’s the same access control pattern for a new data type.
Let’s build a simple flow:
A Memory-Augmented Agent
Here’s the complete flow starting from user message to memory-augmented response:
import { MemoryClient } from "mem0ai";
import { OpenAI } from "openai";
const memory = new MemoryClient({ apiKey: process.env.MEM0_API_KEY });
const openai = new OpenAI();
async function chat(userId: string, userMessage: string) {
// 1. Retrieve relevant memories BEFORE calling the LLM
const memories = await memory.search(userMessage, { user_id: userId });
const memoryContext = memories
.map((m: { memory: string }) => `- ${m.memory}`)
.join("\n");
// 2. Inject memories into the system prompt
const response = await openai.chat.completions.create({
model: "gpt-4o",
messages: [
{
role: "system",
content: `You are a helpful assistant. Here's what you remember about this user:\n${memoryContext || "No memories yet."}`,
},
{ role: "user", content: userMessage },
],
});
const assistantMessage = response.choices[0].message.content;
// 3. Store new memories from this interaction (async — don't block response)
memory.add(
[
{ role: "user", content: userMessage },
{ role: "assistant", content: assistantMessage! },
],
{ user_id: userId }
).catch((err: Error) => console.error("Memory write failed:", err));
return assistantMessage;
}Three things to notice.
Memory retrieval happens before the LLM call, which means retrieved facts are injected into the system prompt, so the model already "knows" them when it generates a response.
Next, Memory storage happens after the response, asynchronously. That means you don't block the user's response to write memories.
Third, the
.add()call handles extraction, consolidation, and storage internally. You send only raw messages; the framework handles the rest.
Scaling and Production Concerns
Here’s where you impress your interviewer.
The happy path of memory is easy. Production-grade memory has edge cases that most engineers don’t think about until they hit them.
Token Budget Management
The biggest production concern is how much memory to inject.
If it’s too little, the agent will forget the critical context. And if it’s too much, your backend system will consume tokens that should be used for the user’s actual request.
The standard budget is 200 tokens for injected memories, which is enough for 5–8 atomic facts. Your retrieval scoring must rank ruthlessly within that budget.
Memory Staleness and Decay
In a production system, coming from a business perspective:
Things change. Facts change. Users switch jobs, change preferences, and abandon projects, customers churn and move to other platforms.
Your memory systems need a recency decay strategy.
A strategy where newer memories score higher than older ones, or deleting memories of 30 days of user inactivity, etc.
Some systems implement explicit expiration: session-scoped memories expire automatically; semantic memories older than N days are deprioritized; episodic memories are pruned to the most recent K interactions.
Privacy and Data Governance
Memory creates a persistent record of user interactions. In regulated industries like healthcare, finance, and legal, this triggers compliance requirements. Your memory system needs:
Delete APIs: Users must be able to delete their memories (GDPR right to erasure).
Scope isolation: One user’s memories must never leak into another user’s retrieval results.
Audit trails: Every memory write, update, and delete must be logged.
Encryption at rest: Memory records contain user data and should be encrypted.
Observability
You can’t manage what you can’t see.
These are some metrics that are worth tracking. You can discuss with the interviewer about their specific use cases:
Memory retrieval latency (p50, p95): Should be under 100ms. If it’s higher, your vector index needs tuning, or your token budget filtering is too complex.
Memory hit rate: What percentage of queries return at least one relevant memory? A consistently low hit rate means your extraction pipeline isn’t capturing useful facts.
Token efficiency: How many tokens do you inject vs how many are used for the user’s actual request? Track the ratio. Full-context approaches consume 26,000+ tokens per conversation. Memory-augmented approaches average ~7,000 tokens per retrieval, which is a 73% reduction.
Consolidation conflict rate: How often does a new fact UPDATE or DELETE an existing memory? A high conflict rate may indicate noisy extraction or a domain where facts change rapidly.
Stale memory retrievals: How often do retrieved memories turn out to be outdated? Track user corrections (“Actually, I no longer work at Acme”) as a signal.
The Framework Landscape in 2026
Let me add this: Discuss these with your interviewer to show awareness of the production landscape
You don’t need to build memory from scratch. The ecosystem has matured.
Mem0: The most widely adopted standalone memory layer. 57K+ GitHub stars. Dual-store architecture (vector + entity index). Supports 20+ vector backends. Works with any LLM stack via REST API. YC-backed, $24M Series A. This is the default recommendation for most teams.
Zep: Production-grade memory with hybrid vector + graph storage. Strong session management. Best for long-running agent sessions where temporal ordering matters deeply.
LangMem (LangChain): Built into the LangChain/LangGraph ecosystem. Supports all three memory types, including procedural. Best when you’re already committed to LangGraph for agent orchestration.
Letta (MemGPT): Tiered memory with self-editing capabilities. The agent can explicitly choose to write, update, or delete its own memories. Most advanced for autonomous agents with long horizons.
Final Answer
“I’d design the memory system as a four-stage pipeline, store in a dual-store architecture combining vector search for semantic retrieval with an entity index for relational traversal, and retrieve using multi-signal scoring that fuses semantic similarity, keyword matching, and entity matching. Memory is scoped by user, session, agent, and organization to enforce isolation. For production hardening, I’d add recency decay scoring, GDPR-compliant delete APIs, scope-level isolation, and observability on retrieval latency, hit rate, and token efficiency.”
Designing a memory system for AI agents sounds like a problem for ML engineers and AI researchers. But as you dig in, you realize it’s built on the same foundations you’ve been working with for years:
Write-ahead pipelines: Extract, consolidate, store. The same pattern as event sourcing
Dual-store retrieval: Vector + structured index. The same architecture as search systems that combine full-text with filters
Scope-based access control: User, session, org. The same isolation model as multi-tenant APIs
Token budget management: Deciding what to include and what to leave out. The same constraint as API response pagination
Lifecycle management: Expiration, decay, pruning. The same TTL logic as cache eviction
Memory for AI agents is not exotic new technology.
It is backend infrastructure for storage, retrieval, access control, and lifecycle, just applied to a new data type.
The things an agent has learned.
So the next time an interviewer asks, “How would you give an AI agent memory?” don’t just say “I’d use a vector database.”
Walk them through the extraction pipeline. Explain how consolidation resolves conflicting facts. Show them the multi-signal scoring function. Talk about what happens when a user exercises their right to be forgotten, and every memory scoped to their ID must be deleted within 30 days.
That’s the answer that shows you’ve built real systems, and not just plugged in a library.
I hope you learned something today: Spread the love. Share this newsletter with at least two of your friends today.
Also, let me know if you enjoy this series and if you want me to continue breaking down interview questions like this.
Whenever you’re ready
There are 3 ways I can help you become a great backend engineer:
1. The MB Platform: Join 4000+ backend engineers learning backend engineering on the MB platform. Build real-world backend projects, track your learnings and set schedules, learn from expert-vetted courses and roadmaps, and solve backend engineering tasks, exercises, and challenges.
2. The MB Academy: The “MB Academy” is a 6-month intensive Advanced Backend Engineering BootCamp to produce great backend engineers.
3. GetBackendJobs: Access 1000+ tailored backend engineering jobs, manage and track all your job applications, create a job streak, and never miss applying. Lastly, you can hire backend engineers anywhere in the world.
LAST WORD 👋
How am I doing?
I love hearing from readers, and I’m always looking for feedback. How am I doing with The Backend Weekly? Is there anything you’d like to see more or less of? Which aspects of the newsletter do you enjoy the most?
Hit reply and say hello — I’d love to hear from you!
Stay awesome,
Solomon (solomoneseme.com)